There is one small problem here though. We knew there were a lot more fish in the pond and you might notice that when we looked closer we also found a lot more red fish that we didn’t catch. How can we do a better job of catching more of the red fish?
 Here is where our other measure, recall, comes into play. Recall awards us for catching more of the red fish. In our first model we didn’t do a very good job of this. So although our precision was good our recall was not so good. Here is where our other measure, recall, comes into play. Recall awards us for catching more of the red fish. In our first model we didn’t do a very good job of this. So although our precision was good our recall was not so good.
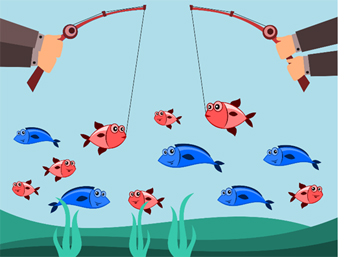
Knowing this we decide to develop a new model using a fishing net and a new bait recipe. The picture below shows the result of our first test with this new model. We caught more of the red fish! Our recall has definitely improved.
Unfortunately you will notice that we caught a lot of blue fish in our net as well. We weren’t trying to catch them but they ended up in our net anyway. We were trying to (or predicted we would) catch all red fish and, while we caught more red fish, many of the fish caught were blue. Our precision has suffered even though we improved our recall.
This is the fundamental trade-off between precision and recall. In our model with high precision (most or all of the fish we caught were red) had low recall (we missed a lot of red fish). In our model with high recall (we caught most of the red fish), we had low precision (we also caught a lot of blue fish).
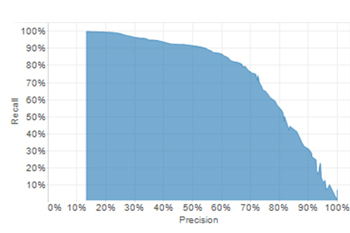 When building a classification model, you will need to consider both of these measures. Trade-off curves similar to the following graph are typical when reviewing metrics related to classification models. When building a classification model, you will need to consider both of these measures. Trade-off curves similar to the following graph are typical when reviewing metrics related to classification models.
The thing to keep in mind is that you can tune the model to be anywhere along the frontier.
For a given model, it is always possible to increase either statistic at the expense of the other. Choosing the preferred combination of precision and recall can be considered equivalent to sliding a dial between more or less conservative predictions (i.e. recall-focused vs. precision-focused). It is important to note that this is for a given model; a better model may in fact increase both precision and recall.
In choosing the correct balance of precision vs. recall you should take a closer look at the problem you are trying to solve.
Let’s relate this back to our supply chain problems, if we are predicting truck driver accidents, we may want a high recall (and be ok with low precision). That is, we want a list that captures all the high risk drivers. We can then do extra training and extra monitoring. And, we are ok that this list may also include a lot of drivers who wouldn’t have had accidents anyway. Our money spent on training and monitoring these already good drivers is worth it if we prevent just one severe accident.
On the other hand, if we are predicting stock outs, we may go for precision. If 200 of my 5,000 items will stock out next month, I may want high precision. That is, I would be happy if you gave me a list of the high precision list of 60 SKUs most likely to stock out. I’ll expedite and take extra measures with these 60 SKUs. I’ll still miss 140. But, that is better than the model giving me a list of 600 SKUs. The list of 600 has most of the 200 in there, but I’m spending time and money on 400 items where there wasn’t going to be a problem.
|